Deeplake Blog
Spin up Postgres in a second: How We Built Serverless PG for Agents.
We built a serverless, PostgreSQL-compatible database. Not a modified PostgreSQL deployment. PostgreSQL provides the interface. Deeplake provides the storage engine. DuckDB provides the query execution.
Table of contents

TLDR: We built a serverless, PostgreSQL-compatible database. Not a modified PostgreSQL deployment. PostgreSQL provides the interface. Deeplake provides the storage engine. DuckDB provides the query execution. The architecture makes a different set of tradeoffs than traditional PostgreSQL. We think those tradeoffs are right for agent workloads: bursty, ephemeral, storage-heavy, and analytical.
Agents need Postgres that could spin up instantly, scale per request, and drop to zero when idle. Not only scale read replicas, but also write replicas. So we didn't just scale Postgres. We rebuilt the system with Deeplake.
In our previous post, we described what we're building: a sandboxed, serverless database that speaks the PostgreSQL wire protocol, spins up per agent, scales with demand, and disappears when idle. This post covers how we built it.
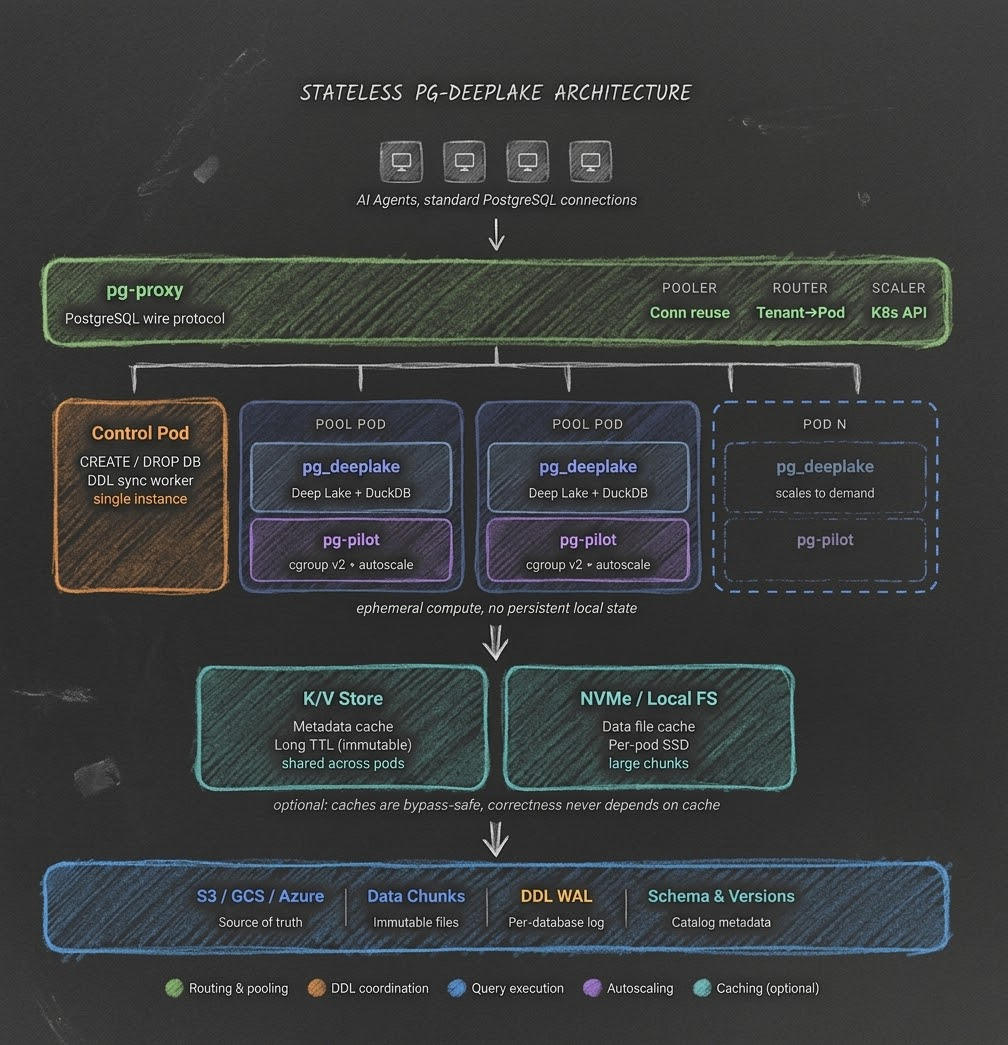
Traditional PostgreSQL is a monolith. Compute, storage, catalog, and connection management are all coupled into a single machine backed by local disk. This makes it reliable for long-lived deployments, but fundamentally incompatible with a serverless model where instances are ephemeral, tenants arrive unpredictably, and idle resources need to cost zero.
We didn't try to bolt serverless behavior onto existing Postgres infrastructure. We took Deeplake's core embedded database engine, its storage format, versioning, and query capabilities, and built a PostgreSQL extension on top of it. PostgreSQL provides the wire protocol and SQL interface that every tool and ORM already speaks. Deeplake provides the storage engine that makes stateless operation possible.
To be clear about what this is: PostgreSQL handles parsing, the wire protocol, authentication, and catalog management. Deeplake replaces the storage layer. DuckDB replaces the query executor. The result is a PostgreSQL-compatible database, not a modified PostgreSQL deployment. Agents connect with psql, ORMs, or any PostgreSQL driver, and get standard SQL back. But under the hood, the engine is different.
Deeplake solves PG write replica scaling without any sharding.
Five Design Decisions That Make It Work
The architecture rests on five departures from how PostgreSQL normally operates.
1. Data Lives in Cloud Object Storage, Not Local Disk
In standard PostgreSQL, table data sits in heap files under PGDATA. This is the core coupling: the data is physically bound to the machine.
In our system, all table data lives in cloud object storage (S3, GCS, or Azure Blob Storage). The local PGDATA directory is stripped down to just the PostgreSQL catalog (DDL metadata, ACLs, roles) and it lives on an ephemeral Kubernetes emptyDir volume.
When a pod dies, no data is lost. Every DDL operation (CREATE TABLE, ALTER TABLE, DROP TABLE) is logged to a separate WAL in cloud storage, one per database. When a new pod picks up a tenant, it replays the DDL log from S3 to reconstruct the local catalog. The actual table data was never local to begin with. This logic is similar to PG WAL, the only difference is that PG deeplake handles only DDL operations.
This separation has a cascading effect on the rest of the architecture. Pods become interchangeable compute nodes. There's no data to migrate, no replication to configure, no disk to resize. No shard to reconcile. Scaling up means starting a new pod that reads the same data from S3. Scaling down means stopping a pod and reclaiming its resources.
Immutable Files Enable Aggressive Caching
Deeplake stores data as immutable chunk files. A write produces new files; existing files are never modified. This eliminates the cache invalidation problem entirely.
We run a three-tier read cache:
- L1. In-process LRU, per connection. Zero-latency hits for hot data.
- L2. Two complementary caches, both benefiting from immutability:
- Shared K/V store for metadata. Long TTL (24 hours default). Since files are immutable, a cached entry can never become stale. TTL is purely for space management, not consistency.
- Local filesystem / NVMe for data files. Large chunk data is cached on the pod's local SSD rather than pushed through the K/V store. This avoids saturating it with multi-megabyte payloads while still providing fast repeated reads.
- L3. Cloud object storage. Source of truth.
Writes go through to cloud storage and simultaneously populate the K/V store, so reads from other pods hit L2 immediately rather than falling through to S3.
In a traditional database, a shared cache layer would be a cache-invalidation nightmare. With immutable storage, it's trivially correct.
Design principle
Every cache layer is optional. The core read/write path never depends on the cache being present. If the K/V store is down, reads fall through to cloud storage. If the local NVMe cache is cold, same thing. The system is correct without any cache. Caching only affects latency, not correctness.
2. pg-proxy: Tenant-Aware Connection Pooler and Router
Every client connection enters through pg-proxy, a Go service that implements the PostgreSQL wire protocol: startup handshake, SCRAM-SHA-256 authentication, query cancellation, and TLS negotiation. It serves three roles: connection pooler, tenant router, and cluster scaler.
Tenant routing. The database name in the connection string is the tenant identifier (org ID). pg-proxy maps each tenant to one or more backend pool pods.
When a connection arrives for database=org_123:
- Connection pool check. If a pre-authenticated backend connection to
org_123exists in the pool, pg-proxy authenticates the client directly (no round-trip to the backend), sends synthetic startup response messages using captured backend metadata (PID, secret key, parameter status), and reuses the connection. - Routing table check. If the tenant already has assigned pods, pg-proxy uses least-connections routing to pick one. If the busiest pod exceeds the per-pod connection threshold, it asynchronously provisions a sibling pod, up to a per-tenant cap.
- Cold provisioning. If this is an unknown tenant, pg-proxy claims an idle pod from a pre-warmed buffer, connects to it, runs
CREATE DATABASE "org_123"(~200ms), labels the pod in Kubernetes, and routes the connection.
Scale-to-zero. When a tenant's last connection disconnects, an idle timer starts. If no connection arrives before it fires, pg-proxy drops the database on every assigned pod, removes the Kubernetes labels, and returns the pods to the idle buffer. For multi-pod tenants, excess pods have their own drain timers. When a single pod's connections drop to zero while other pods still have traffic, that excess pod is individually reclaimed.
State restoration. Tenant-to-pod mappings are persisted as Kubernetes pod labels. When pg-proxy restarts, it reads labels from the Kubernetes API to reconstruct its routing table. As a fallback, it queries pg_database on unlabeled pods to catch cases where the label write failed during provisioning.
Control pod separation. One dedicated pod runs with DDL synchronization enabled. This is the control pod, and it is the system's serialization point for schema state. pg-proxy routes database=postgres connections directly to it, bypassing the pool entirely. The control pod handles database creation, deletion, and writes DDL operations to the shared log. It does not serve tenant query traffic. Pool pods are stateless workers that read from this log on demand.
3. PostgreSQL Core Patch: Demand-Driven DDL Synchronization
This is the decision that most directly shapes the architecture's behavior.
The problem. In a multi-pod deployment where each pod has its own local PostgreSQL catalog, how do you keep catalogs in sync? When one pod creates a table, other pods need to know about it. The obvious approach is proactive synchronization: a background worker that polls a shared catalog on an interval. But polling means overhead on every pod, synchronization delays, and complexity around conflict resolution.
Our approach. We patched PostgreSQL's source code to add two new extension hooks:
resolve_missing_relation_hook, called when PostgreSQL cannot find a relation (table, view) in the local catalog.resolve_missing_column_hook, called when PostgreSQL cannot find a column in a known relation.
These hooks don't exist in upstream PostgreSQL. We added them.
The pg_deeplake extension registers callbacks on both hooks. When a query references a table that doesn't exist locally, instead of returning an error, PostgreSQL fires the hook. Our callback reads the shared DDL log from cloud storage, replays any DDL statements that originated from other instances (CREATE TABLE, ALTER TABLE ADD COLUMN, etc.), and returns. PostgreSQL retries the catalog lookup and finds the table.
Key insight
Pool pods never proactively sync catalog state. There is no polling interval, no background DDL worker, no wasted S3 round-trips. A refresh happens only when a query asks for something the local catalog doesn't have. If no query touches a missing resource, no sync occurs. Zero overhead.
Thundering herd protection. Under high concurrency (hundreds of backends), multiple sessions may simultaneously hit a missing relation and trigger the hook. A sync gate coordinates this: the first backend performs the S3 refresh, concurrent backends spin-wait and reuse the result. This collapses potentially hundreds of simultaneous S3 requests into one.
What the control pod does. The single control pod runs a background sync worker that writes DDL operations to a shared log in cloud storage as they happen. It's the only instance that proactively writes to this log. Pool pods only read from it, and only on demand.
4. Query Engine: Deeplake Storage + DuckDB Execution
The pg_deeplake extension is not a thin wrapper that forwards queries to PostgreSQL's executor. It replaces the execution layer.
PostgreSQL handles: wire protocol, parsing, authentication, catalog management, and the client-facing interface. The user connects with psql, sends standard SQL, and gets standard result sets back.
The extension handles: query execution. When a SELECT arrives, the extension intercepts it via PostgreSQL's planner hook, translates it into an execution plan backed by Deeplake's storage layer, and executes it using DuckDB's columnar engine. Internal adaptors feed data from Deeplake's chunk format into DuckDB, and convert DuckDB's output back into PostgreSQL tuples. Deeplake's native columnar storage format aligns well with DuckDB's columnar execution model, so data flows between the two without expensive format conversions.
This means the SQL semantics are not identical to vanilla PostgreSQL. The execution engine is DuckDB, not the PostgreSQL executor. For the agent workloads we target (structured storage, retrieval, analytical queries, BM25 search), the overlap is large. But features like SELECT FOR UPDATE, advisory locks, LISTEN/NOTIFY, and some edge cases in type coercion behave differently or are not yet supported. We are explicit about this because we think honesty about the compatibility boundary matters more than claiming full PostgreSQL equivalence.
The pod is a pure compute node. It fetches data from cloud storage (through the cache hierarchy), processes the query, returns results. No local data to protect, no WAL to flush, no checkpoints to manage.
5. pg-pilot: Sidecar-Driven Vertical and Horizontal Autoscaling
Each pool pod runs pg-pilot as a sidecar container, a small Go process that monitors the pod and makes scaling decisions.
Monitoring. pg-pilot samples three signals every 5 seconds:
- CPU utilization from Linux cgroup v2:
cpu.statusage delta normalized by allocated cores. - Memory usage from cgroup v2:
memory.current(anon + page cache) as a ratio ofmemory.max. We use total memory, not just anonymous. Page cache counts toward the cgroup limit and can trigger OOM. - Active backends from PostgreSQL:
pg_stat_activitycount.
Samples are stored in sliding-window ring buffers for time-windowed decision making.
Vertical scaling. pg-pilot uses Kubernetes In-Place Pod Resize (KEP-1287) to change the pod's CPU and memory requests without restarting it. PostgreSQL keeps running, connections stay alive. Pods start at a small tier and scale up to medium as load increases. Tiers are defined as CPU + memory pairs and are extensible. Adding a new tier is a one-line change.
Scale-up is aggressive. Any single trigger fires:
- CPU >75% for 30 seconds (6 consecutive samples)
- Memory >80% for 15 seconds (3 consecutive samples)
- Active backends >12 for 30 seconds
Scale-down is conservative. All three must hold:
- CPU <20%, memory <40%, backends <3 for a full 5-minute window (60 samples)
A 2-minute cooldown prevents oscillation between tiers. Configs can be customized per deployment.
Vertical-to-horizontal escalation. When a pod is at the maximum tier and scale-up triggers still fire, pg-pilot can't scale vertically anymore. It sets a Kubernetes label on the pod. pg-proxy reads this label during its pod discovery loop and responds by provisioning a sibling pod for the tenant, automatically transitioning from vertical to horizontal scaling.
Pressure backpressure. When memory exceeds 70% of the limit, pg-pilot signals pg-proxy to stop routing new tenants to that pod. Existing connections continue, but no additional tenants are routed to an overloaded pod. When memory drops below the threshold, the pod re-enters circulation.
Idle scale-down. When a pod has zero databases (no tenant assigned), pg-pilot immediately scales it to the small tier. Idle pods should be cheap.
Putting It Together: The Fast Boot
Traditional PostgreSQL cold start requires initdb (catalog initialization), extension installation, and configuration. That's roughly 12–14 seconds. For a serverless system that provisions databases on-demand, this is unacceptable.
We eliminate this with a baked container image using a multi-stage Docker build:
Build stage: Run initdb, start PostgreSQL, install the pg_deeplake extension into template1 (so every future CREATE DATABASE inherits it), apply configuration via ALTER SYSTEM, perform a clean shutdown preserving a valid WAL checkpoint.
Final stage: Copy the fully initialized data directory into the image.
At runtime, the entrypoint copies this baked directory to an emptyDir volume, injects runtime configuration (S3 root path, TLS, superuser password), and starts PostgreSQL directly. No initialization, no extension setup. Cold start drops from 14 seconds to 1 second.
We install the extension on template1 rather than postgres because our metrics exporter (postgres-exporter) connects to the postgres database, and its concurrent queries against the extension's sync worker cause deadlocks.
End-to-End Lifecycle
Here's the full sequence when an AI agent gets a database:
- Connect. Agent connects to pg-proxy with
database=org_123. - Provision. Connection pool miss, routing table miss. pg-proxy claims an idle pod, runs
CREATE DATABASE "org_123"(~200ms), labels the pod. - Query. Agent sends SQL. The pg_deeplake extension fetches data from S3 through the cache hierarchy, executes via DuckDB, returns PostgreSQL tuples.
- Vertical scale. pg-pilot detects sustained high CPU. Patches the pod from
smalltomediumin-place. No restart, no connection drop. - Horizontal scale. Pod hits max tier, still under pressure. pg-pilot signals pg-proxy, which provisions a second pod for
org_123. Connections load-balanced across both. - Wind down. Agent disconnects. After the idle timeout, pg-proxy drops the database on both pods, removes labels, returns pods to the idle buffer.
- Cluster scale-down. Idle buffer exceeds maximum. pg-proxy reduces the Kubernetes deployment replica count. Excess pods terminated.
From the agent's perspective, it connected to a Postgres database, ran SQL, and disconnected. The provisioning, scaling, and teardown were invisible.
How is it different?
| Traditional PostgreSQL | Stateless PG Deeplake | |
|---|---|---|
| Data location | Local heap files | Cloud object storage (S3/GCS/Azure) |
| Local disk role | Data + catalog + WAL | Catalog + ACLs only (ephemeral) |
| Cold start | 12–14 seconds (initdb) | 1 seconds (baked image) |
| DDL sync | Streaming replication | Demand-driven via PG core hooks |
| Query execution | PostgreSQL executor | DuckDB engine via internal adaptors |
| Caching | Shared buffers (local) | In-process + K/V store + NVMe (immutable) + cloud |
| Vertical scaling | Restart required | In-place pod resize, no downtime |
| Horizontal scaling | Read replicas with replication lag | Identical stateless pods, automatic |
| Idle cost | Full instance | Zero: pods reclaimed, databases dropped |
| Tenant isolation | Long-lived databases | On-demand provisioning and teardown |
How does it compare against Neon/Lakebase?
Neon has demonstrated serverless Postgres can work. In fact, prior to Neon, AWS Aurora Serverless already shipped it back in 2019. We took a different approach. Here we outline key differences of Neon compared to Deeplake.
There are three dimensions.
- Write Replicas: Neon only picks a single primary node to route writes, while it scales read-only replicas. Your agents not only read, but also write. Deeplake in contrast makes every replica writable, while resolving consistency on object storage.
- Version Control: Neon's branching is copy‑on‑write on a database-level. You can branch from a parent and diverge, but there is no built‑in mechanism to automatically reconcile changes from a child back into the parent. Instead Deeplake, provides granular table level version control with mergable branches.
- Multimodal: Since You can store images, videos, PDFs without blowing the memory of the database.
While Neon is good for web apps, Deeplake is focused on agentic data workloads.
Benchmarks
These are production measurements, not synthetic benchmarks. They include network round-trips to cloud storage, cache warming, and DDL replay.
- Cold start (pod to first query): ~1 seconds. Traditional
initdbtakes 12-14 seconds. - Database provisioning (
CREATE DATABASE): ~200ms per tenant. - Write-to-query visibility: ~500ms average (2,000-row table, 1,200-row append batch, measured from individual row insert completion to row visible via SELECT).
- Scale-to-zero and resume: an idle agent's database is dropped after the timeout. When the agent reconnects, the database is re provisioned and the first query completes in under a second. The agent does not need to know this happened.
Now Postgres Scales with Agents
The question we started with was simple: can you give every AI agent its own database, scale it on demand, and pay nothing when it's idle?
An agent connects. A database exists in 200ms. Queries run. The pod scales from 2 to 64 cores without dropping a connection. The agent leaves. Everything is reclaimed. The next agent gets the same experience.
Postgres scales under a second.