Deeplake Blog
Your Agents Are Drowning in Quicksand. Give Their Data a Sandbox.
Databases were built for applications. Deeplake is built for agents. A sandboxed, serverless Postgres instance that spins up with every agent, scales with the swarm, and dies when the job is done.
Table of contents

TLDR: Databases were built for applications. Deeplake is built for agents. A sandboxed, serverless Postgres instance that spins up with every agent, scales with the swarm, and dies when the job is done. And unlike traditional databases, Deeplake doesn't just store rows and columns. Your agents can store and retrieve images, video and PDFs, alongside structured data.
Fast and fully multimodal. Pay for what your agents actually use
Hitting the "Context Wall"
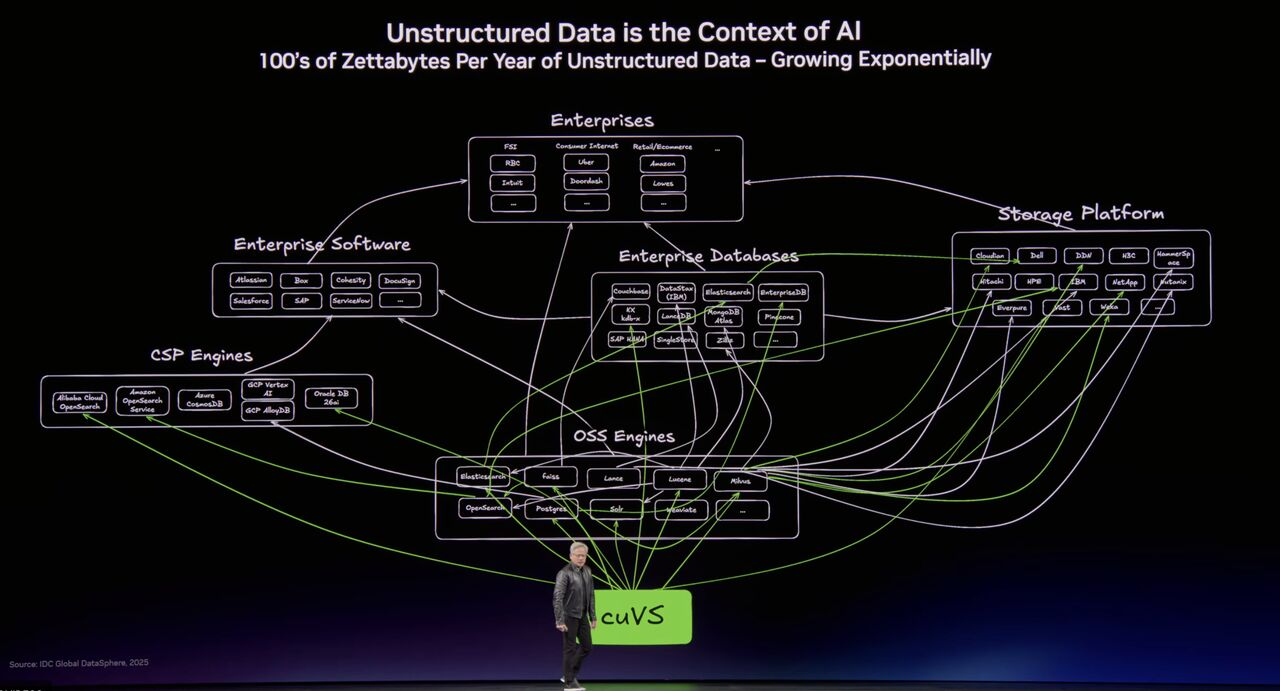
Every six months, the industry converges on a new answer for agent memory. And every six months, it breaks.
Context windows keep getting bigger. The infrastructure feeding them hasn't kept up. In 2024, the playbook was straightforward: give a LLM a vector database, stuff relevant chunks into the prompt, call it memory. It worked, until agents needed to do more than answer questions. By early 2025, the industry pivoted: point the model at a real database, let it write SQL. That was better, but provisioning and managing a database per agent didn't scale. So we pivoted again. The filesystem became the default. Give the agent bash, a scratch directory, and let it write memory.md. It's the primitive we settled on, not because it was right, but because it was easy.
Now we're two stuck between bad options.
Filesystems that don't scale past a single agent. Flat files are fine for code and docs. But the moment you have a swarm of agents doing concurrent reads and writes, need to query millions of rows of interaction logs, or want schemas that prevent agents from hallucinating their own data structures, the filesystem falls apart. It was never designed to be a database. We just started treating it like one.
Legacy databases weren't designed to be handle agents. The obvious fix, give every agent a real Postgres instance, is equally broken. Traditional databases take minutes to provision, bundle compute and storage into expensive monoliths, and have no concept of scaling to zero. You're paying for a running database whether the agent is working or idle for the next six hours. Also the state can't be shared.
Of course, Your Data Agents Need Context, but how?
Agents need a living, breathing context layer that ties together messy enterprise data, semantic definitions, and human-refined rules.
-
Problem: Agents need safe, isolated scratchpads to execute code against the data and test workflows. They need to experiment without breaking production or stepping on other agents' toes.
Solution: Because compute and storage are decoupled, Deeplake can instantly clone a high-fidelity branch of not only a database but also table. The agent gets its own sandboxed replica to mutate, test, and verify. If it fails, the branch is thrown away. If it succeeds it merges into the main branch.
-
Problem: Agent workloads are spiky by nature. An agent might sit idle for hours, then spawn a swarm of 50 sub-agents that need massive concurrent throughput for 30 seconds.
Solution: Serverless Postgres compute spins up in seconds when the harness loop starts, scales up to handle the swarm, and scales completely to zero when the harness spins down. You are also not bottlenecked by a single writer replica. You don't pay for idle database machines.
-
Problem: Agents run for days or weeks, generating massive amounts of intermediate state, logs, and context that overflow traditional database storage limits.
Solution: Because the actual data lives in cloud object storage (S3) rather than an expensive attached disk (EFS), the agent essentially has an infinite, durable memory bank.
Multimodality is the final piece of the puzzle
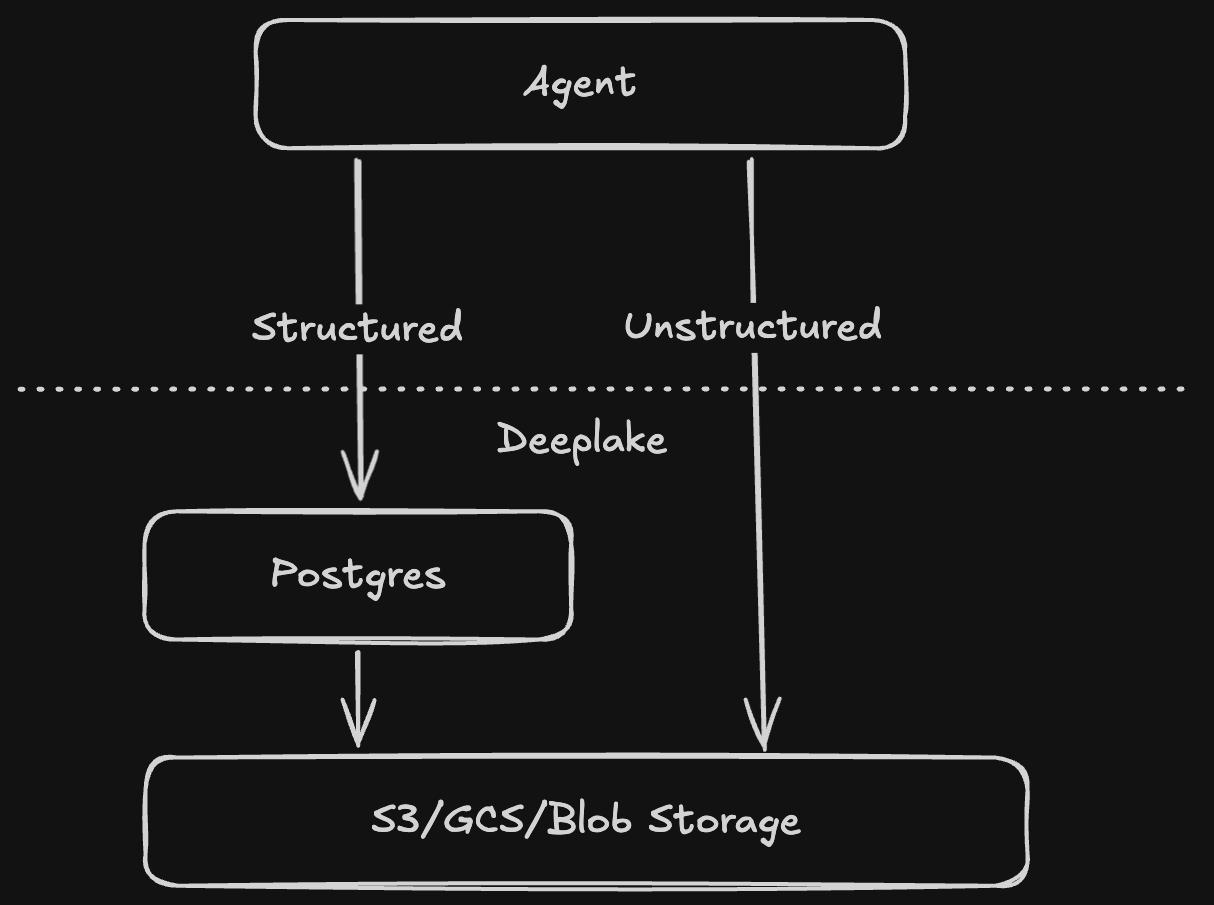
Agents require one final piece of the puzzle that traditional databases do not provide. Databricks Lakebase solves for the infrastructure scale problem, but its built for traditional tables with read only scaling. Enterprise data is not just built for reading rows and columns. They not only think in text, but in vectors, images, audio and video.
Deeplake is like Lakebase, but natively multimodal, unstructured-first and built for writes at scale, not just read replicas.
It collapses the need to have fragmented data tooling. Instead of forcing your agent to juggle a vector database for embeddings, an S3 bucket for images, and a messy JSON file for relational state, Deeplake unifies them. It provisions a sandboxed, multimodal Postgres instance for every single agent harness.
- Unified Modalities: The agent can write SQL to join its relational memory (past user preferences) with vector similarity searches (finding relevant documentation) and visual data (referenced image) all in the same isolated sandbox.
- Speculative Branching: The agent thinks steps ahead, and should not have to worry about destructive operations on the table level. ****With Deeplake, agents will not only read replicas at scale, but also write replicas. Data is shared across agents, so they can cooperate.
- Harness Integration: It sits perfectly inside the execution logic. When your orchestration logic spawns a sub-agent, Deeplake instantly provisions its isolated database context.
Get Started Along with Your Coding Agent
Get DEEPLAKE_API_KEY from deeplake.ai and set it as environment variable
pip install deeplake # npm install deeplake
# install skills
npx skills add activeloopai/deeplake-skills
# execute
claude "create a Deeplake table from documents and enable lexical search."Then ask Claude Code or Codex to
- "Ingest these PDFs into Deeplake with page and filename metadata."
- "Create a Deeplake table for these images and captions, then index embeddings."
- "Ingest these video files into Deeplake and make them queryable by metadata."
Data is the State, Deeplake builds the data runtime for AI.
As models get smarter, they will require less hand-holding from the harness. But the underlying physical reality of data persistence will not change. Models cannot hold the entire world in their context windows.
Opposed to stateless compute, data is hard. Data itself is the state.
If we give models a sandboxed REPL environment to safely execute stateless compute, it is logically inconsistent to deny them a sandboxed, elastic database to safely execute durable state. Give your agents the multimodal memory they need to actually do work.
Data is the State, Deeplake builds the data runtime for AI.